Proposed Framework
AVSR-Diff is a decoupled framework built upon a pre-trained single-image super-resolution LDM. A trainable ControlNet guides the frozen denoising U-Net for scale-agnostic latent denoising, where the TGFR module aligns and gates recurrent features across adjacent frames to suppress flickering. The denoised latent sequence is then rendered by a Continuous Video Decoder that uses SAFR to modulate high-frequency details based on the target scale, followed by a coordinate-based INR for continuous querying.
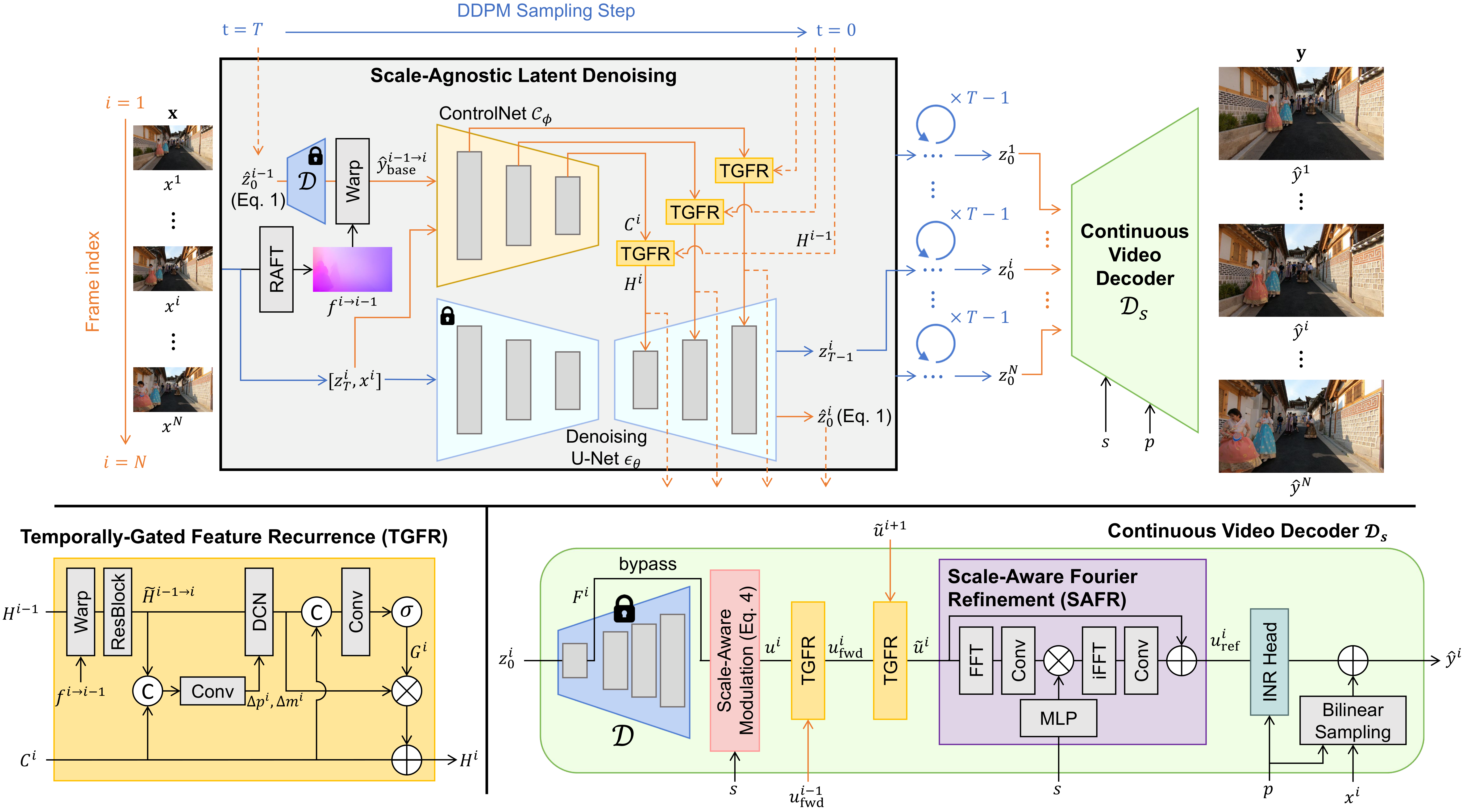
Figure 1. Overview of the proposed AVSR-Diff: scale-agnostic latent denoising with the Temporally-Gated Feature Recurrence (TGFR) module, and a continuous video decoder with the Scale-Aware Fourier Refinement (SAFR) module.