Abstract
Video
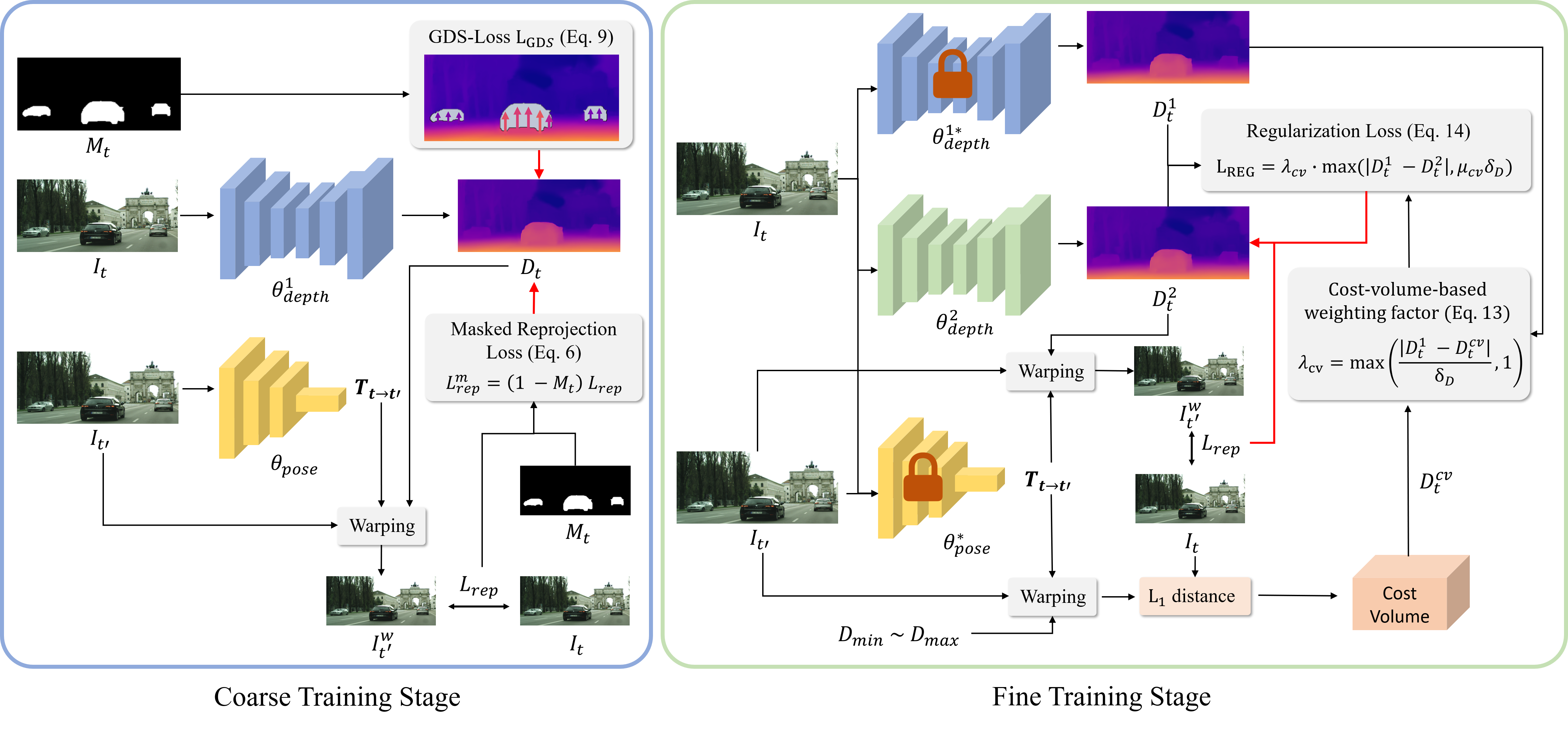
Method Overview
We propose a novel coarse-to-fine training strategy to effectively handle moving object problems in self-supervised learning of monocular depth estimation. In the coarse training stage, we utilize the ground contacting prior as a self-supervision for depth estimation on dynamic objects, presenting Ground-contacting-prior Disparity Smoonthess Loss (GDS-Loss). The ground contacting prior is based on an observation that most objects classified as dynamic in outdoor scenes, such as cars, bicycles, or pedestrians, invariably tend to make contact with the ground, thereby sharing similar depth at their ground contact points. In the fine training stage, we further refine the depth estimation network to capture detailed depth of dynamic objects. We introduce a regularization loss with a cost-volume-based weighting factor to avoid inaccurate learning from the reproejction loss on the moving object regions.
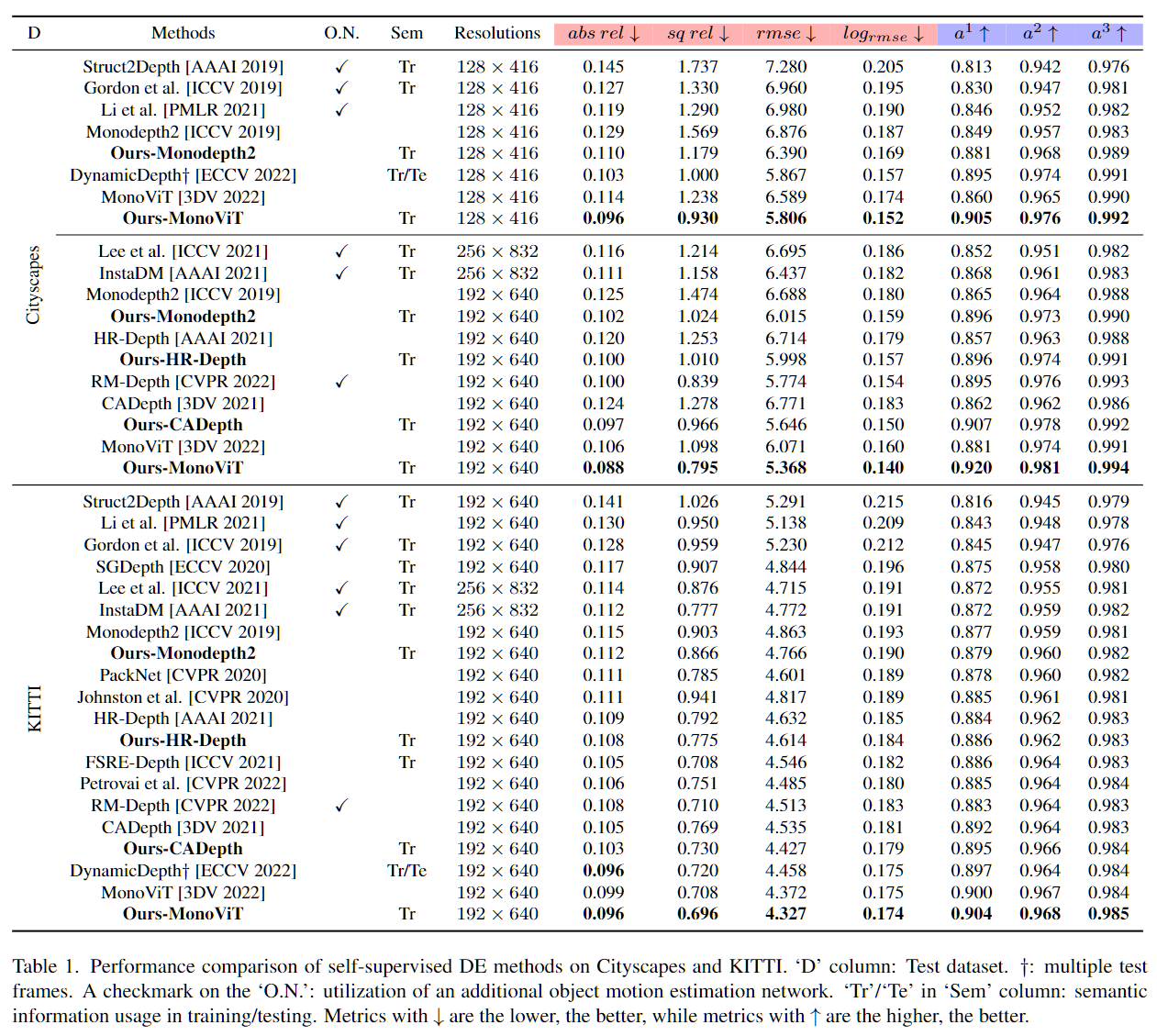
SOTA Comparison
Our coarse-to-fine training strategy significantly improves the depth estimation performance of existing methods including Monodepth2 [ICCV 2019], HR-Depth [AAAI 2021], CADepth [3DV 2021] and MonoViT [3DV 2022]. Each model trained with our training strategy is denoted as Ours-Monodepth2, Ours-HR-Depth, Ours-CADepth, Ours-MonoViT. Our training strategy is easily integrated into those methods and enhances depth estimation performance on both Cityscapes and KITTI datasets. Moreover, Ours-MonoViT achieves state-of-the-art depth estimation performance on both datasets.
3D Point Cloud Reconstructions

BibTeX
@inproceedings{moon2024ground,
title={From-Ground-To-Objects: Coarse-to-Fine Self-supervised Monocular Depth Estimation of Dynamic Objects with Ground Contact Prior},
author={Moon, Jaeho and Bello, Juan Luis Gonzalez and Kwon, Byeongjun and Kim, Munchurl},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={10519--10529},
year={2024}
}