Neural Radiance Fields (NeRF), initially developed for static scenes, have inspired many video novel view synthesis techniques. However, the challenge for video view synthesis arises from motion blur, a consequence of object or camera movement during exposure, which hinders the precise synthesis of sharp spatio-temporal views.
In response, we propose a novel dynamic deblurring NeRF framework for blurry monocular video, called DyBluRF, consisting of a Base Ray Initialization (BRI) stage and a Motion Decomposition-based Deblurring (MDD) stage. Our DyBluRF is the first that handles the novel view synthesis for blurry monocular video with a novel two-stage framework.
In the BRI stage, we coarsely reconstruct dynamic 3D scenes and jointly initialize the base ray, which is further used to predict latent sharp rays, using the inaccurate camera pose information from the given blurry frames. In the MDD stage, we introduce a novel Incremental Latent Sharp-rays Prediction (ILSP) approach for the blurry monocular video frames by decomposing the latent sharp rays into global camera motion and local object motion components. We further propose two loss functions for effective geometry regularization and decomposition of static and dynamic scene components without any mask supervision. Experiments show that DyBluRF outperforms qualitatively and quantitatively the SOTA methods.
Overview of our DyBluRF framework. To effectively optimize the sharp radiance field with the imprecise camera poses extracted from blurry video frames, we design our DyBluRF consisting of two main procedures (Algo. 2 in Supplemental) of (a) Base Ray Initialization (BRI) Stage (Sec. 3.3 and Algo. 1 in Supplemental) and (b) Motion Decomposition-based Deblurring (MDD) Stage (Sec. 3.4).
To validate the quality of deblurring monocular video novel view synthesis of our DyBluRF, we compare it with the existing dynamic novel view synthesis methods including HexPlane, HyperNeRF, 4DGS as well as the existing static deblurring novel view synthesis methods DP-NeRF and BAD-NeRF. All methods are optimized using the newly synthesized Blurry iPhone Dataset. For the existing static deblurring novel view synthesis methods, DP-NeRF and BAD-NeRF, which are originally designed solely for static novel view synthesis, we incorporate time instances as additional inputs, resulting in DP-NeRF$_t$ and BAD-NeRF$_t$, to make them synthesize dynamic components for a fair comparison.
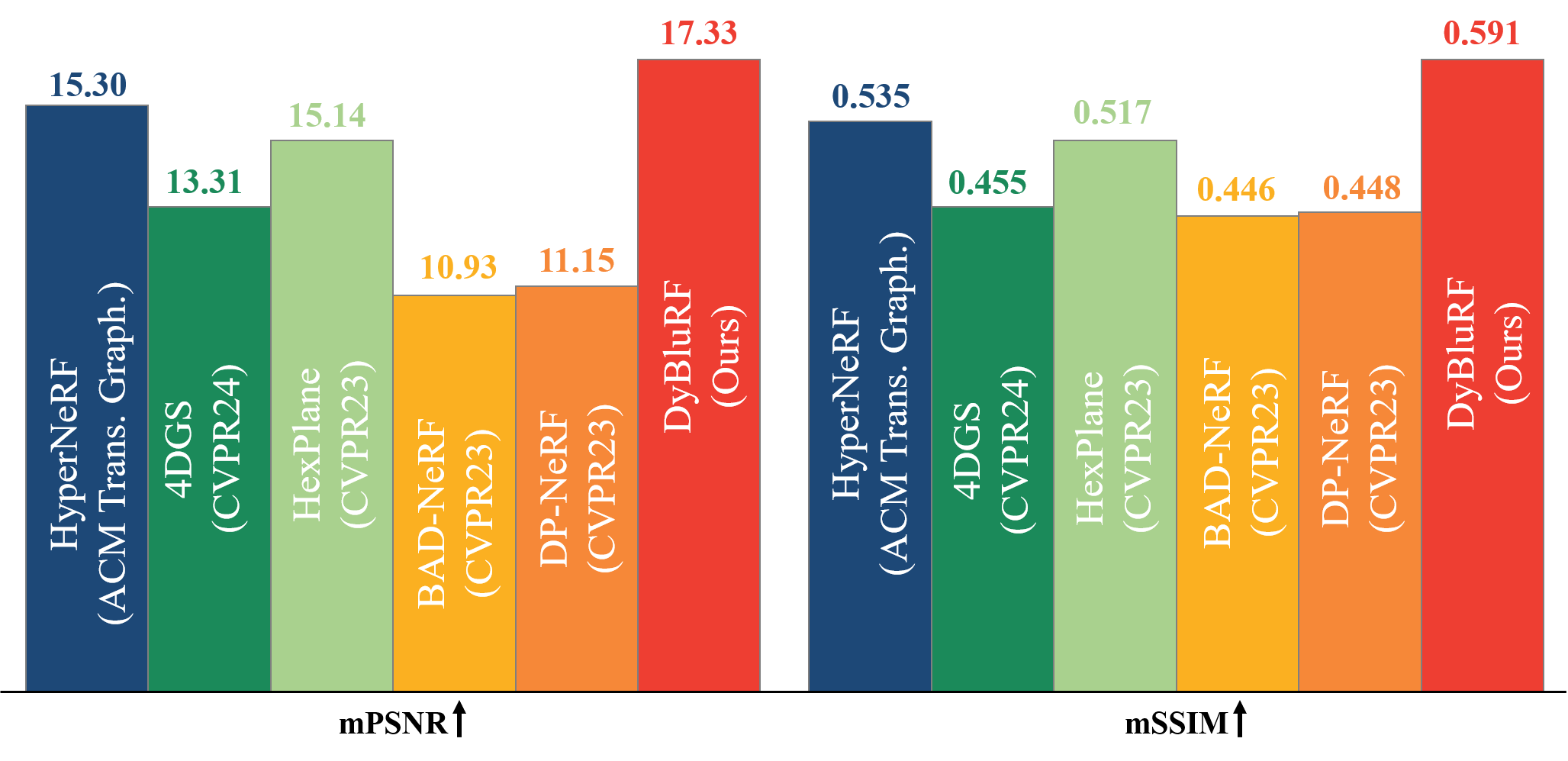
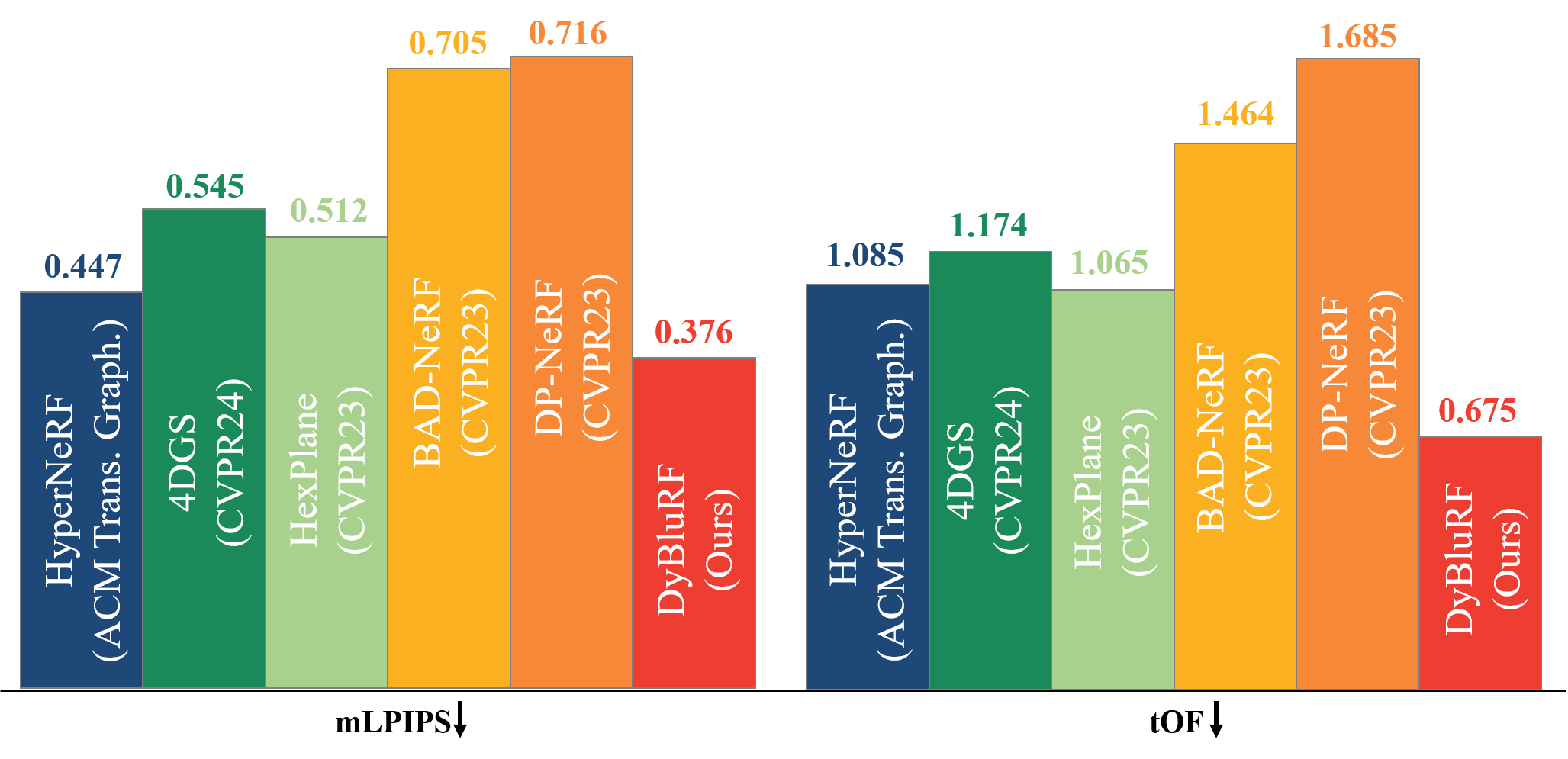
We utilize the co-visibility masked image metrics, including mPSNR, mSSIM, and mLPIPS, following the approach introduced by Dycheck. These metrics mask out the regions of the test video frames which are not observed by the training camera. We further utilize tOF to measure the temporal consistency of reconstructed video frames.
The below table shows the robustness of DyBluRF across varying dataset capture qualities. We evaluate the dynamic novel view synthesis performance of T-NeRF, HyperNeRF, and DyBluRF by training each method with two datasets: the original iPhone dataset or our newly synthesized Blurry iPhone dataset. As shown, both T-NeRF and HyperNeRF experience substantial performance declines across all metrics with the Blurry iPhone dataset compared to their performance with the original iPhone dataset, underscoring the challenge posed by our Blurry iPhone dataset for dynamic novel view synthesis without a deblurring module. In contrast, DyBluRF maintains consistent results between the two datasets across all metrics, demonstrating its robustness to different degrees of blurriness.
Red
andblue
denote the best and second best performances, respectively.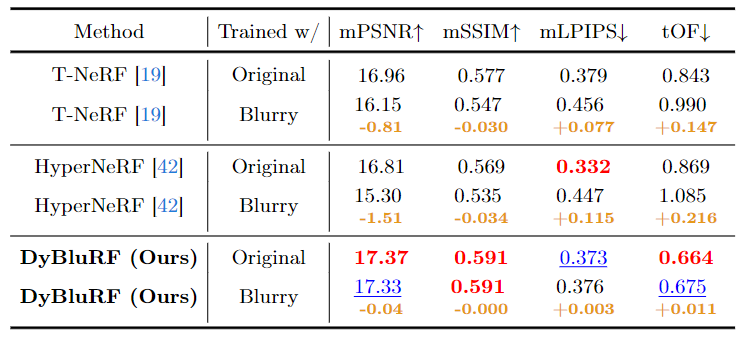
As shown in the below figure, DyBluRF adaptively predicts latent rays to stably model the physical blur process, maintaining the sharpness of the base ray's rendering color $\hat{\mathbf{C}}^{full}$ regardless of the degrees of blurriness in the training frames. Other methods fail to learn the reliable sharp reconstruction from blurry training frames due to the absence of a temporal-aware deblurring module.
Our blurry dataset and implementation are built on top of Dycheck codebase. Dycheck consists of casual captures with strict monocular constraint for dynamic view synthesis.
This work was supported by IITP grant funded by the Korea government (MSIT) (No. RS2022-00144444, Deep Learning Based Visual Representational Learning and Rendering of Static and Dynamic Scenes).
@article{bui2023dyblurf,
title={DyBluRF: Dynamic Deblurring Neural Radiance Fields for Blurry Monocular Video},
author={Minh-Quan Viet Bui and Jongmin Park and Jihyong Oh and Munchurl Kim},
journal={arXiv preprint arXiv:2312.13528},
year={2023}
}