SOTA Comparison: Novel View Synthesis on LLFF Dataset
We provide extensive experimental results on the LLFF and Blender datasets to show the effectiveness of our method in comparison with recent SOTA methods. Also, we present a comprehensive ablation study that supports our design choices and main contributions. More results are shown in Supplemental. We evaluate the rendering quality of our method by three widely used metrics: Peak Signal-to-Noise Ratio (PSNR), Structural Similarity (SSIM) and Learned Perceptual Image Patch Similarity (LPIPS) . When it comes to SSIM, there are two common implementations available, one from Tensorflow (used in the reported metrics from NeRF, MobileNeRF, and IBRnet), and another from sci-kit image (employed in ENeRF, RSeN, NLF). We denoted the metrics from Tensorflow and sci-kit image as SSIM_t and SSIM_s, respectively. Similarly, for LPIPS, we can choose between two backbone options, namely AlexNet and VGG. We present our SSIM and LPIPS results across all available choices to ensure a fair and comprehensive evaluation of our method's performance.
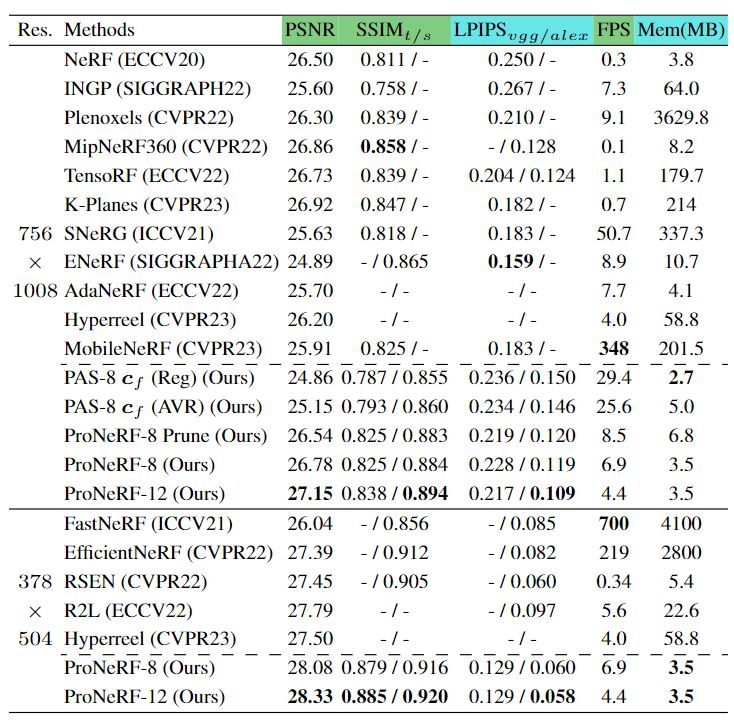
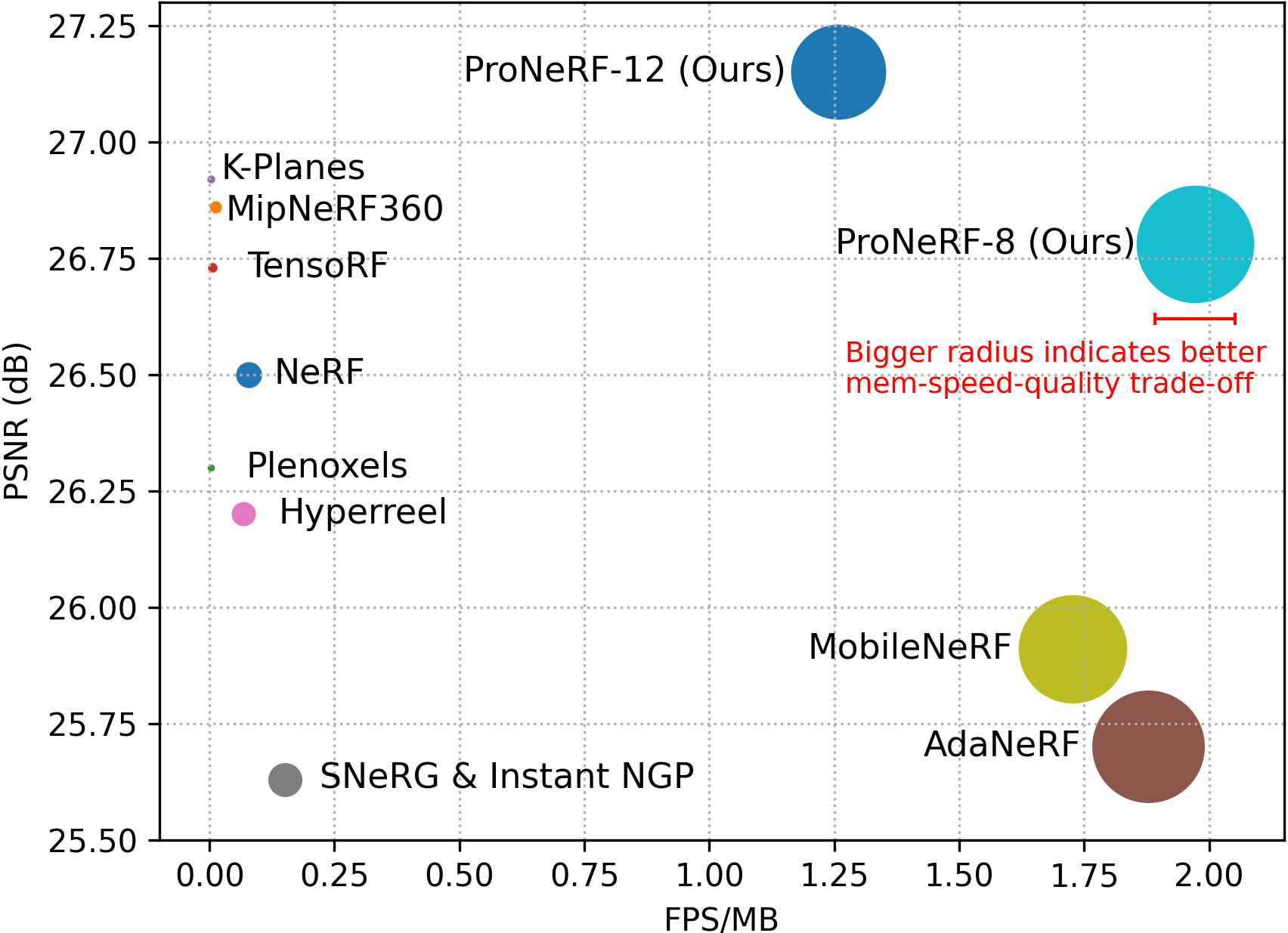
Performance trade-off of neural rendering (memory, speed, quality) on the LLFF dataset. Our ProNeRF yields the best performance profiling (memory, speed, quality) trade-off.
Qualitative comparisons for the LLFF dataset. Zoom in for better visualization.