Proposed Single-View NVS Method
Modeling View-Dependent Effects (VDE)
(a) We synthesize target VDEs (black dots) induced on the input view I by re-sampling I along the negative depth region of the epipolar line (green dots). In contrast, 3D geometry does present disparities between views (blue dots). (b) VDEs present disparities relative to their reflective surfaces in the opposite direction than the projection of the reflective surface itself. (c) and (d) VDE disparity due to novel camera poses is proportional to the reflective surface disparity. The closer the reflective surface, the larger the VDE disparity.
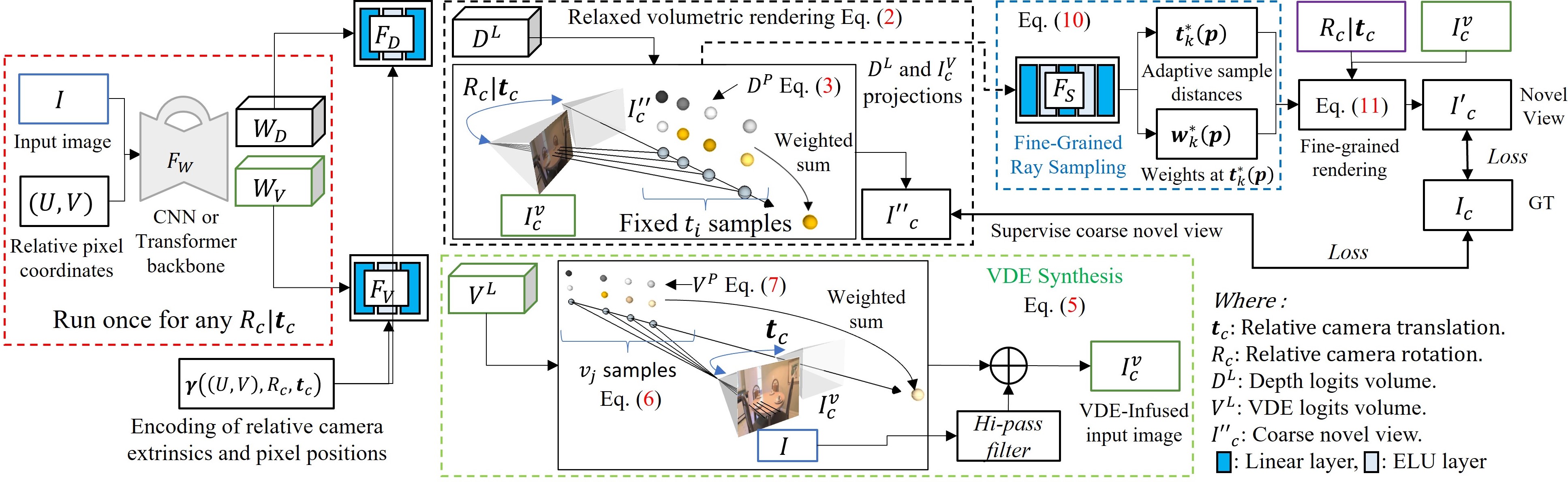
Overall Network Architecture
The proposed NVSVDE-Net models VDEs at the input view as the negative scene disparities under the target camera motion Rc | tc. Novel views are estimated in two stages. Firstly with coarse fixed ray samples ti, then with refined adaptive sampling distances t*k.
Results on RealEstate10k
Our results on the RealEstate10k dataset (RE10k).
Results on the MannequinChallenge Dataset
Our results on the MannequinChallenge dataset (MC).
Extreme NVS
We trained our NVSVDE-Net to render views that are at most 16 frames apart from the single-image input. In this experiment, we render views equivalent to 40 frames apart from the input view. Despite the inherent challenges associated with extreme Novel View Synthesis, our method consistently produces realistic views, albeit with certain observable artifacts, as anticipated in any single-view NVS framework.