Academic website of KAIST VICLab, under the advisory of Prof.Munchurl Kim, Korea Advanced Institute of Science & Technology (KAIST), Korea.
Our research of interest includes deep-learning-based computer vision, computational image & video processing as well as image & video understanding and 2D/3D video coding.
Our recent intensive works focus on Computer Vision research
[1] in the fields of natural image and video restoration: (1) super-resolution, (2) frame interpolation, (3) SDR-to-HDR inverse tone mapping, (4) image in-painting, (5) depth estimation, (6) image deraining, (7) image dehazing, (8) video motion debluring; (9) generative restoration of old photos,
[2] in the fields of 3D image/video reconstruction: (1) depth estimation, (2) optical flow estimation, (3) camera pose estimation, (4) dynamic neural radiance field (NeRF) and Gaussian splatting learning of video for novel view synthesis;
[3] in the fields of satellite images: (1) PAN sharpening, super-resolution and cloud removal of Electro-Optical (EO) images, (2) super-resolution, detection and classification of Synthetic Aperture Radar (SAR) image targets, (3) SAR-to-EO image-to-image translation learning, etc.
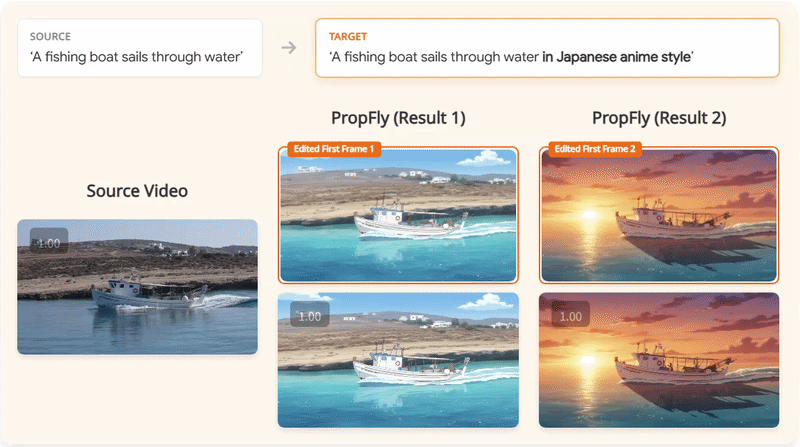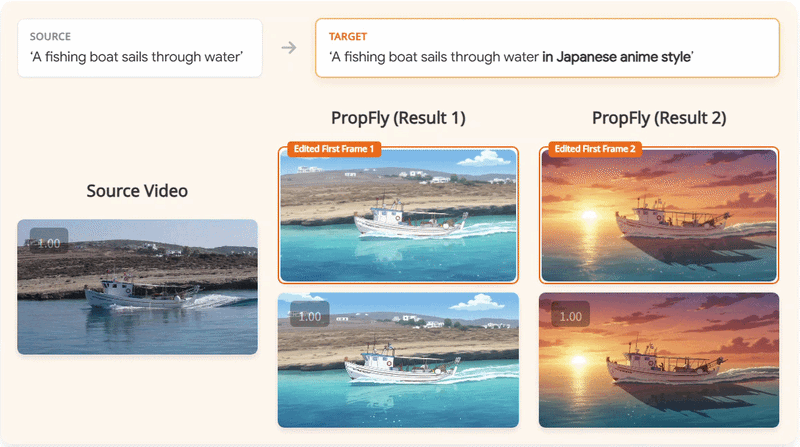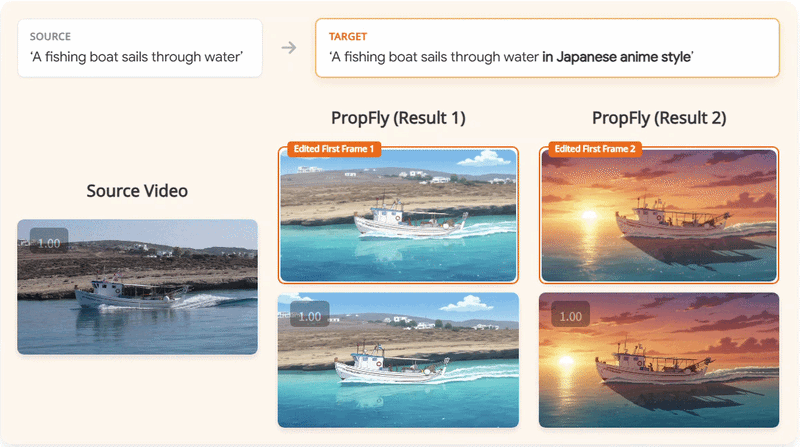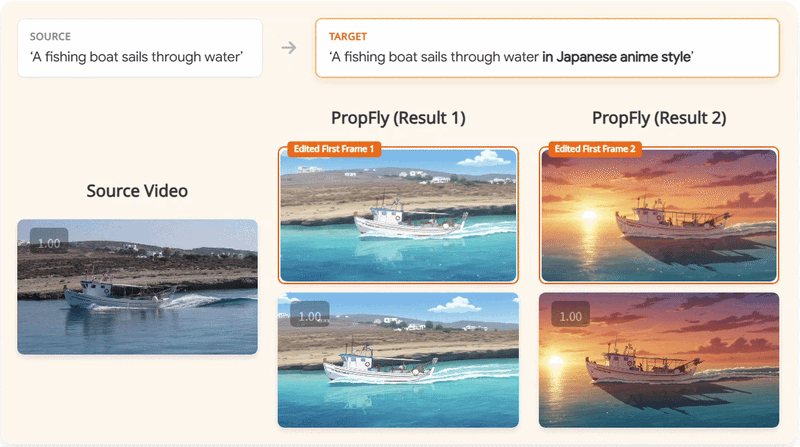
We present PropFly, a training pipeline for Propagation-based video editing, relying on on-the-Fly supervision from pre-trained video diffusion models (VDMs) instead of requiring off-the-shelf datasets.
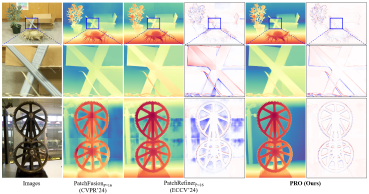
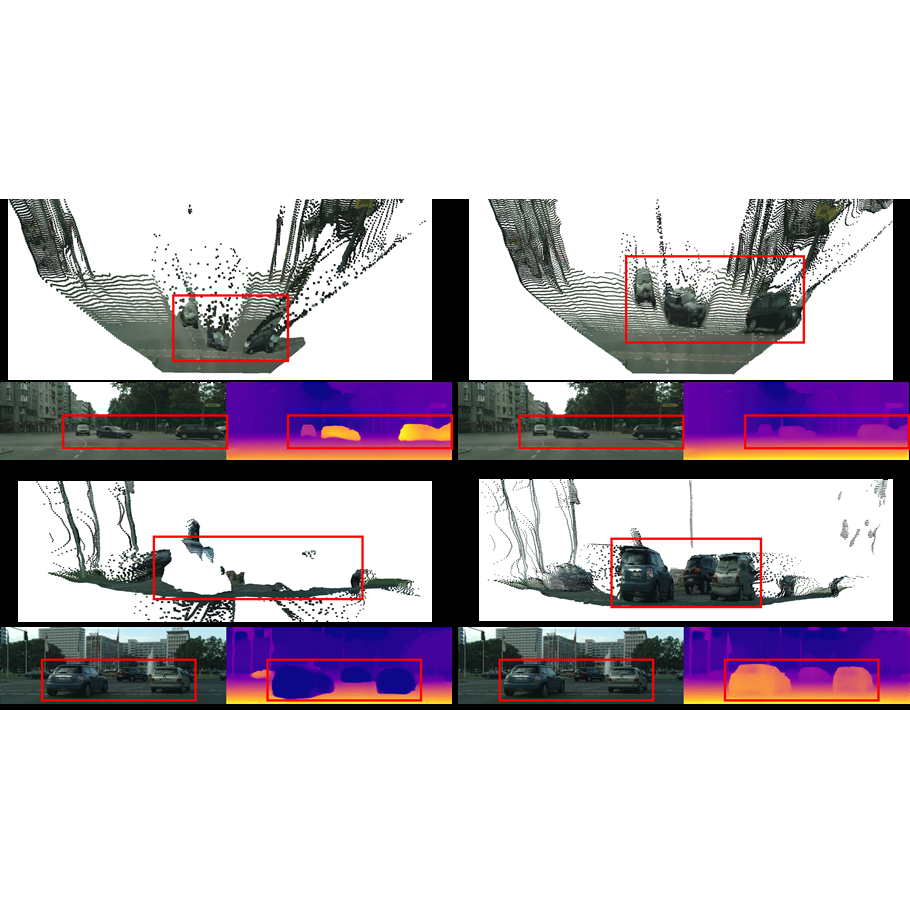
We present One Look is Enough, a framework for zero-shot monocular depth estimation on high-resolution images that utilizes Grouped Patch Consistency Training and Bias Free Masking to achieve seamless patchwise refinement with high efficiency.
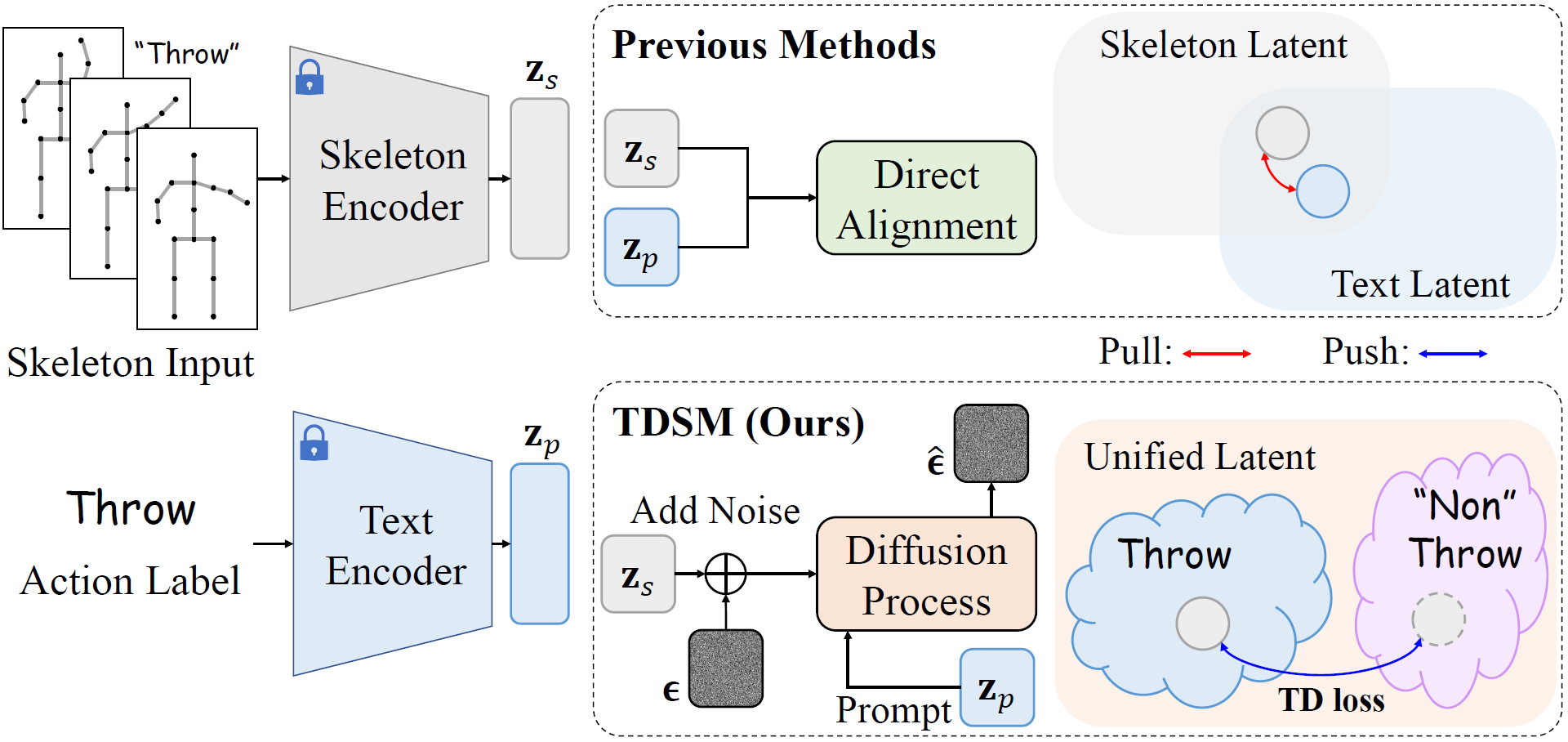
TDSM introduces the first framework to apply diffusion models and to implicitly align the skeleton features with text prompts (action labels) by fully taking the advantage of excellent text-image correspondence learning in generative diffusion process, thus being able to learn fused discriminative features in a unified latent space.
PAN-Crafter propose Modality-Adaptive Reconstruction (MARs), a unified reconstruction framework that enables robust learning from misaligned PAN-MS image pairs by dynamically generating both HRMS and PAN images.
C-DiffSET proposes the first framework to fine-tune a pretrained LDM for SET tasks, effectively leveraging their learned representations to overcome the scarcity of SAR-EO image pairs.
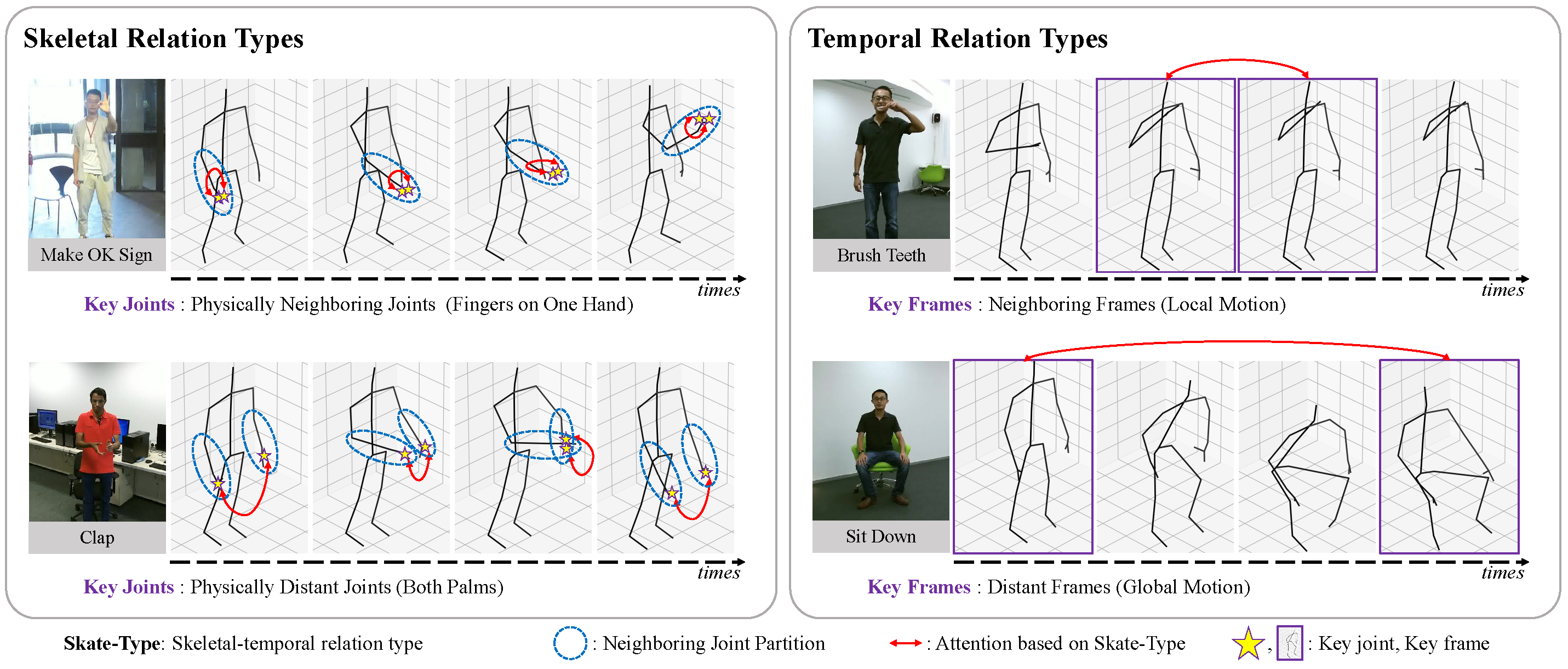
SkateFormer proposes a partition-specific attention strategy (Skate-MSA) for skeleton-based action recognition that captures skeletal-temporal relations and reduces computational complexity.